Clojure programs start slowly because they load the clojure.core namespace before doing anything useful. Loading the clojure.core namespace loads the Java class files for all of the functions in clojure.core and sets up Vars to point to new class instances corresponding to each function.
This is slow. Simple desktop Clojure programs start about 35x more slowly than their Java counterparts. Clojure Android apps start as little as 6x more slowly than their Java counterparts, but the base start time is much higher so the problem is worse.

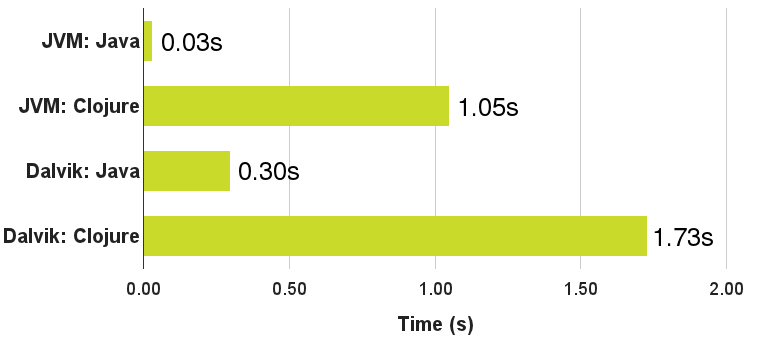
In the very best case a Clojure on Android app currently starts in about 1.7 seconds. More normal cases likely take at least 3-5 seconds. Jakob Nielsen in his book Usability Engineering suggests a few rules of thumb for UI response time. A user perceives as much as 0.1 seconds as instantaneous. Delays of more than 0.2 seconds are noticeable and delays of more than one second should have some indication to the user that something is happening. Ten seconds or more and you will lose your user’s attention completely.
Currently Clojure on Android apps fall in the “noticeably slow” range. This is also true for command line tools like Leiningen, even on reasonably fast computers. Reducing startup delay to 0.5 seconds on Android would get us into the range of noticeable delay not requiring a loading screen. This means we’re looking for about a 4-6x improvement in boot times.
This amount of speedup will probably require dramatic changes to the Clojure runtime. About half of the boot time on the desktop is due to loading the Java classes themselves. This suggests that the Clojure bootstrap process is just doing too much. We need to do dramatically less work during the Clojure runtime boot process.
So here are a few ideas for how to improve Clojure start time. These are mostly suggested by other people and I have added my own thoughts regarding each of them. I break them out broadly into three categories: do less work, do it faster, or do it later.
Do Less Work
What work are we doing in the bootstrap process that is unnecessary? How can we eliminate this work to speed up our bootstrap process?
1. Stripped, application-specific runtime
Most of the work of bootstrapping Clojure programs relates to setting up dynamic variables for Clojure functions. Many of these functions will never be used, but dynamic features like runtime evaluation and compilation require access to all functions in the Clojure language.
But what if we decide that we don’t need runtime evaluation or compilation, at least for production? Then there’s no sense in keeping around all of these extra functions that are never used. This idea is to generate a specific stripped production runtime for the application being developed. Instead of including the normal Clojure runtime/compiler with your app, the app would use this new stripped runtime. The runtime would differ from the normal runtime in the following ways:
- All core functions that are not used are stripped out from the Clojure runtime and therefore not loaded in core initialization.
- Runtime compilation and evaluation functions are removed.
- Unused metadata is also removed.
This is a fairly easy idea to test. Take a few Clojure programs, see what clojure.core functions they rely on, strip the remaining functions from clojure.core source, recompile the Clojure runtime, and run the program using the new runtime.
Using this approach I was able to cut the run time for a Hello World program in half. This could possibly be reduced even further. This is a great improvement, but it is essentially the best case scenario. This best case scenario is not good enough. Most programs will use a much larger fraction of clojure.core and will see much smaller speedups.
Do It Faster
How can we do the same bootstrap work faster? In what ways can we optimize this process?
2. Optimized runtime loading
This idea I vagely label “optimize runtime loading”. Currently the Clojure runtime (by which I mostly mean the clojure.core namespace) is compiled in almost the exact same way as any other Clojure code. It is also run in the same way as any other namespace. While this is elegant from a language development perspective, is there some way we could optimize clojure.core loading so that it works faster?
Every time a Clojure program is run it does the exact same work in setting up a Namespace object for clojure.core. Is there some way we can do this work once, save the result to a single binary file, and then load the file at one time? I don’t know. It seems like there could be a way but I don’t know what it is.
Otherwise maybe there are shortcuts we could take for compiling clojure.core that would not work in the general case for Clojure code. I don’t know what those shortcuts might be, but I think they exist.
Do It Later
Do we need to do all of this work on boot? Why can’t we defer setup work until we actually need it?
3. Modularized clojure.core
This idea is, on the face of it, quite simple. Break clojure.core into smaller namespaces. Overall Clojure 1.5.1 has 591 publicly available functions or variables via ns-publics. Is this a lot? I don’t know. Direct comparisons with non-functional languages is a bit difficult. Scala and Java would appear to have fewer classes and methods in their core libraries and Ruby appears to have more functions, but I cannot say for sure.
The Clojure core namespace does provide a lot of functionality: bitwise operations, regular expressions, type inspection, concurrency operations, multifunctions, Java interop, operations for the core data structures, structs, transients, namespaces, vars, hierarchies, protocols, metadata, compilation and evaluation. Probably a number of these could be broken into separate namespaces.
But here’s the challenge. Here’s my chart of the function interdependencies in clojure.core:

Each of those nodes is a function in clojure.core. The lines indicate which other functions in clojure.core the function relies on.
Now tell me how that breaks down cleanly into separate namespaces.
There’s one cluster on the bottom left that relies solely on defn. That could maybe be pulled out. On the other hand, I believe those functions work mostly by deferring to clojure.lang.RT, so pulling them out might not help much.
If there are too many interdependencies in clojure.core, then breaking it down further would make loading time worse rather than better. If a function depends on several functions in other namespaces then loading multiple namespaces takes longer than loading one.
4. Lazy initialization of Clojure functions
This is an idea presented by galdolber, who has worked on a Clojure compiler for Objective C. Here’s my understanding of how this idea might work.
Clojure core bootstrapping sets up a Var to point to every function in the clojure.core namespace. In Java bytecode the setup work looks like this:
Var const__cons = RT.var("clojure.core", "cons");
AFn const__consMeta = RT.map(metaForCons);
const__cons.setMeta(const__consMeta);
const__cons.bindRoot(new core.cons());
The end result looks kind of like this:

The Namespace object for clojure.core is set up with a mapping of Symbols to Vars corresponding to functions. Each Var in turn points to its own metadata and an instance of the Java class file which implements the Var functionality.
When you call a function, it is done like this (in pseudo-Java bytecode):
// (cons args)
RT.var("clojure.core", "cons").getRawRoot().invoke(args);
This first fetches the core namespace and then fetches the Var in the namespace corresponding to cons. From the Var we can then grab the current value with getRawRoot and invoke it.
But why do we need to set up everything beforehand when a namespace is loaded? Why can’t we just load and set up functions as we need them? galdolber’s idea would move the Vars into their corresponding class instances and initialize them only when they are first used. This also sounds fairly similar to Laurent petit’s comment on my other post. I picture the result something like this:

We keep Clojure’s dynamic binding features, as we still use mutable Namespaces and Vars, while pushing the time to load and initialize functions to the first time they are used.
This could be a good idea. It could also cause hiccups in performance. Right now all loading penalties are paid cleanly when a namespace is loaded. Under this idea if you use a function that has dependencies across clojure.core you may pay the loading time penalty at an awkward point.
This could also be combined with the stripped runtime idea. We throw out unneeded functions and load the functions we do need lazily. It could work. But is it enough?
In the Objective C case galdolber quotes a speedup from 2.3 seconds to 900 milliseconds. This is about a 2.6x speedup. Stripping our runtime could give a little more. A similar speedup in Android would drop our fastest startup times from about 2 seconds to 770 milliseconds. The average case could be twice that. This is good, but based on those numbers it’s not good enough. Prove me wrong, galdolber.
Do Less Work, Faster, and Later
The problem with many of the above ideas is that they don’t seem to go far enough. We need dramatic speed improvements. This probably requires dramatic changes to the way Clojure works.
5. Lean JVM runtime
This idea makes the most dramatic changes but also has the most compelling potential. This is also what Daniel Solano Gómez has been proposing all along and echoes some of what mikera has been saying. It has taken me several months to understand what is going on well enough to appreciate this idea.
Clojure dynamism
Clojure is a dynamic language. Two key features that Clojure supports as a dynamic language are dynamic binding of vars and namespaces and dynamic incremental compilation and evaluation.
Dynamic binding is in some ways a surprising feature for a language that touts its immutability. All variables defined with def and functions defined with defn are implemented using mutable Vars. The Vars are stored within mutable Namespaces. Either can be changed at any time. This means that every function call requires at least two levels of indirection: first get the Namespace, then the Var, then the function itself, and finally call the function. Refer to the diagram further up.
The second important feature is dynamic incremental compilation and evaluation. Clojure is a very flexible language. Almost anything that can be done at compile time can also be done at run time. It includes built in evaluation [1] and compilation. Among other things, this enables the power of the Read Eval Print Loop (REPL). Combined with dynamic binding of namespaces and namespace variables, this gives a programmer a substantial amount of power to change their program while it is running.
In development, both of these features are very useful. Dynamic binding allows you to redefine functions for testing and development and gives more tools to work with external libraries that you do not control. Runtime evaluation and compilation combined with dynamic binding enable the short feedback loops of a powerful REPL development environment.
But how important are these features in production? Dynamic compilation seems to be used hardly at all in production. Use of dynamic binding in production is usually discouraged. In the case of Android development, dynamic recompilation is not even possible in the same way. When using a Clojure library from a Java environment it seems unlikely these features would be useful. In both of these last cases fast startup time and runtime performance seem more important.
The Idea
The premises of a lean JVM runtime are the following:
- The program is Ahead of Time (AOT) compiled.
- After compilation the program does not need to be redefined.
- Run time performance is the main priority.
Based on these premises, the following changes would be made to the Clojure compiler and runtime:
- Dynamic binding is removed. Namespaces compile to classes. Namespace variables and functions compile to static fields or methods. The Var is probably removed entirely.
- Dynamic compilation and evaluation are removed. Functions that rely on runtime compilation and evaluation such as
eval,compile,load, and so forth are eliminated.
How will this improve Clojure startup times?
- When variables compile to static methods and fields there are fewer classes to load and they can be loaded lazily. This means there is a lot less to load at boot and boot times should be dramatically shorter.
- Immutable functions and namespace variables can be directly referenced. This removes the two levels of indirection from fetching mutable namespaces and fetching mutable vars. For boot time or when loading classes, this means there is a lot less work to do.
How else could this improve Clojure performance?
- Removing Var and Namespace indirection should significantly improve runtime performance.
- Static compilation enables dead code elimination. The size of packaged Clojure apps could be reduced significantly.
- Static compilation enables other compiler optimizations that are not possible under a dynamic, “nothing is certain” environment.
But is it still Clojure?
In theory the default Clojure compiler and runtime could be used for development. The same REPL development story would work, tests could redefine variables, and any other dynamic features would be available.
At run time, however, it would be a different story. A large laundry list of features would be dropped from the Clojure runtime. The lean runtime would be fast but lack the elegant symmetry and power of near equivalent run time and compile time features. It could also limit some of the interop with existing libraries which rely on dynamic rebinding of variables.
In many ways this would be similar to ClojureScript. ClojureScript has a subset of Clojure functionality. Among other differences, it lacks runtime evaluation and compilation, vars, and much of the runtime access to variables. This lean runtime would provide a similar subset of Clojure functionality, while taking it further in some respects.
It also looks like Common Lisp has corresponding features that allow the developer to specify what is compiled for speed and what is interpreted for flexibility. Some helpful Common Lisp guru could tell if these features are relevant. Scala would be another source for inspiration, as it generates static code much different than Clojure’s code.
Summary
The Clojure bootstrapping process needs to do much less work for Clojure programs to start in a reasonable time for library or Android applications. I have presented here five different ideas for achieving faster start times in Clojure:
- Stripped, application-specific runtime
- Optimized runtime loading
- Modularized clojure.core
- Lazy initialization of Clojure functions
- Lean JVM runtime
The only idea that I feel goes far enough to achieve reasonable performance on Android is the lean JVM runtime idea. It is probably the most difficult of these ideas to implement but it is the idea I will try to move forward with.
There are lots of unanswered questions here. The implementation details of the lean JVM runtime are still vague. What do you think? Am I missing important details? Am I in completely over my head? Are there other good ideas out there? What would you like to see?
[1] Clojure is cited as a purely compiled language in a number of places. But then why does this look so much like interpretation? Is Java bytecode involved in some way that I can’t see right now? Update: as per Alex Miller’s comment, yes, it is actually compiled.
- Edit 2014-03-19: removed all references to interpretation as per Alex Miller’s correction.
</small>